Metaphor vs. Literal Classification
Can predicted brain responses distinguish metaphorical from literal language? Figurative language engages additional right-hemisphere and temporal regions — this experiment tests whether TRIBE v2 encodes that distinction.
Summary
TRIBE v2 predicted brain responses distinguish metaphorical from literal language with 95% accuracy on a held-out test set (20 unseen stimuli, AUC 1.000). The classifier was trained on 80 stimuli using a Pipeline with StratifiedKFold cross-validation (78.8% CV accuracy, 0.901 AUC), then evaluated on 20 completely held-out stimuli — 10 metaphors and 10 literal statements it never trained on. Only 1 out of 20 holdout stimuli was misclassified — a literal sentence predicted as metaphor. This suggests TRIBE v2 encodes a distinction between figurative and literal language processing in its predicted brain patterns, and that this signal generalizes to unseen text.
Key metrics
Holdout Acc
95.0%
Accuracy on 20 held-out stimuli (10+10)
Holdout AUC
1.0
ROC AUC on holdout set — perfect separation
CV Accuracy
78.8%
5-fold StratifiedKFold on 80 training stimuli
CV AUC
0.901
ROC AUC on Pipeline CV
Train
80.0
40 metaphor + 40 literal for training
Holdout
20.0
10 metaphor + 10 literal held out
Features
20,484
Cortical vertices per sample
Regularization
L1 (C=1.0)
SAGA solver, lasso penalty
Confusion matrix
Actual
Predicted
Classification report
| Class | Precision | Recall | F1 | Support |
|---|---|---|---|---|
| Literal | 0.90 | 1.00 | 0.95 | 10 |
| Metaphor | 1.00 | 0.90 | 0.95 | 10 |
| Macro avg | 0.95 | 0.95 | 0.95 | 20 |
PCA projection
PC1 (28.1% var)
PC2 (21.0% var)
Discriminative brain regions
98.3%
353 / 20,484
Metaphor-predictive
Literal-predictive
Regions identified via L1-regularized logistic regression weights mapped onto the Destrieux cortical atlas (fsaverage5). Percentages reflect each region's share of total cortical weight for its category (excluding medial wall vertices).
Interested in what these regions mean? Read the full discussion — a region-by-region analysis comparing these findings to published neuroscience literature.
Figures
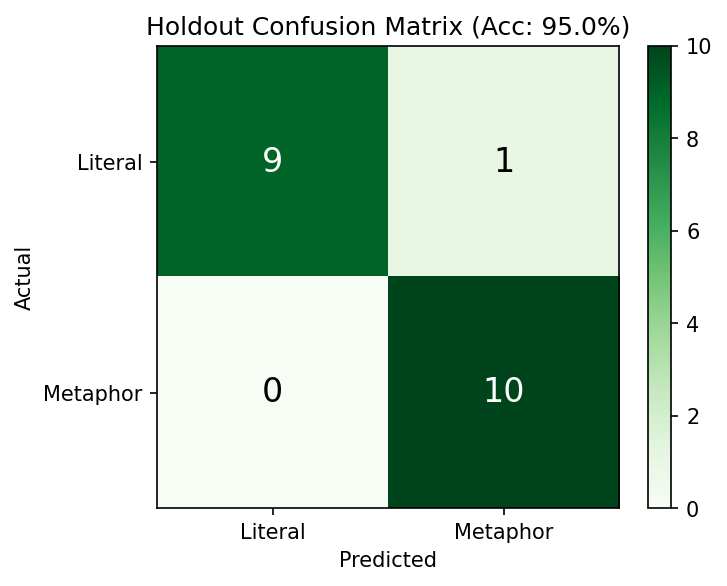
Holdout confusion matrix — Unseen stimuli
Gold-standard test on 20 held-out stimuli (10 metaphor + 10 literal). 9/10 literal correct, 10/10 metaphor correct. Only 1 literal sentence was mistaken as metaphor.
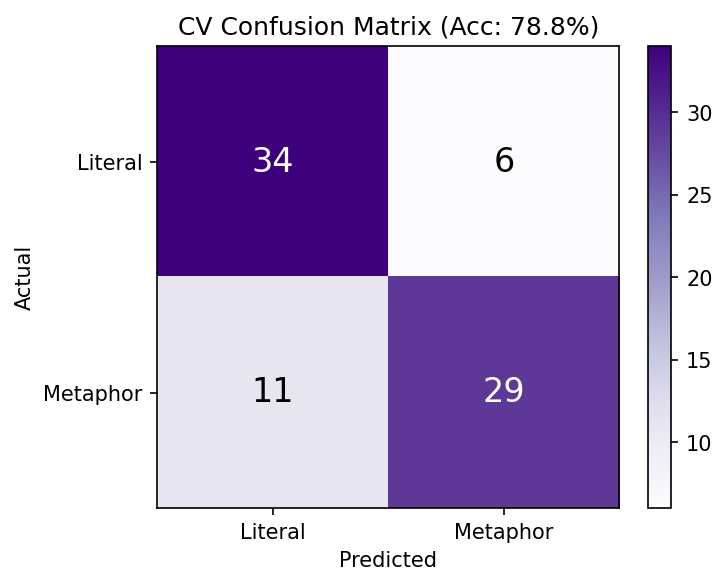
CV confusion matrix — Training stimuli (StratifiedKFold)
5-fold StratifiedKFold cross-validation on 80 training stimuli with Pipeline (scaler inside CV). 78.8% accuracy — 17 misclassifications out of 80.
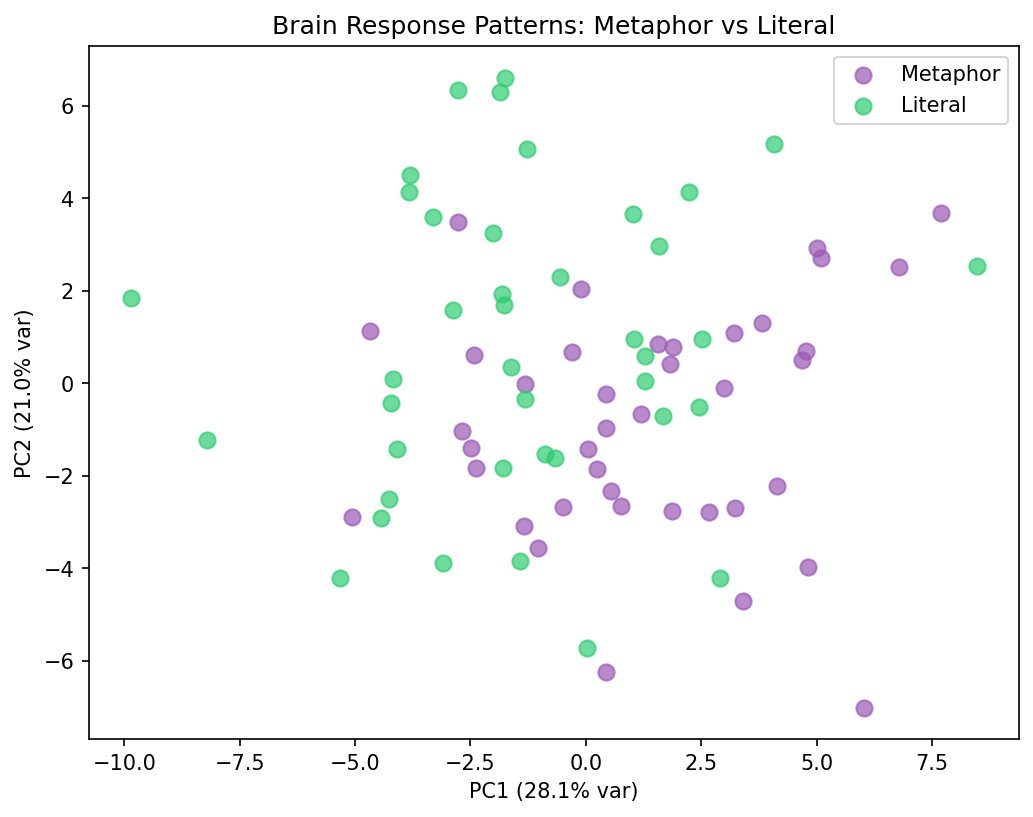
PCA scatter — Brain response patterns
First two principal components of brain activation vectors. Metaphor and literal clusters show separation consistent with the classification performance.
Classifier weights — Left lateral
Logistic regression weights projected onto the left lateral brain surface. Warm regions are metaphor-predictive.
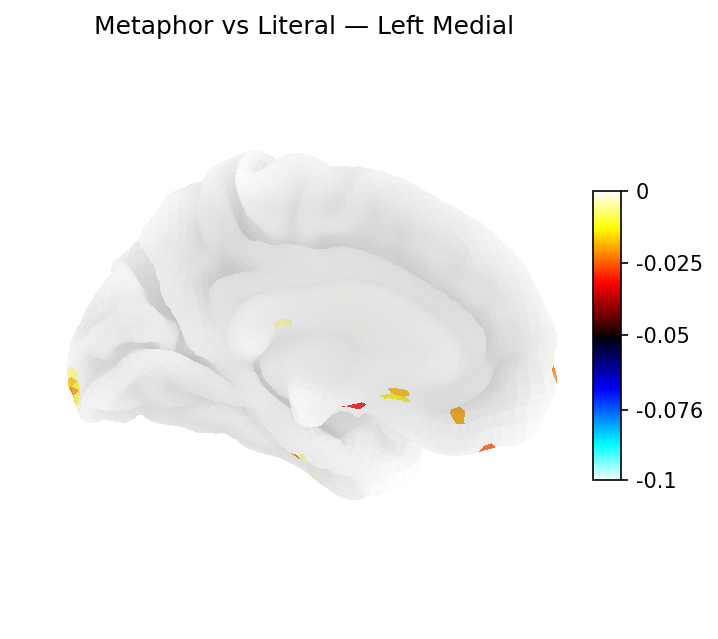
Classifier weights — Left medial
Logistic regression weights on the left medial surface.
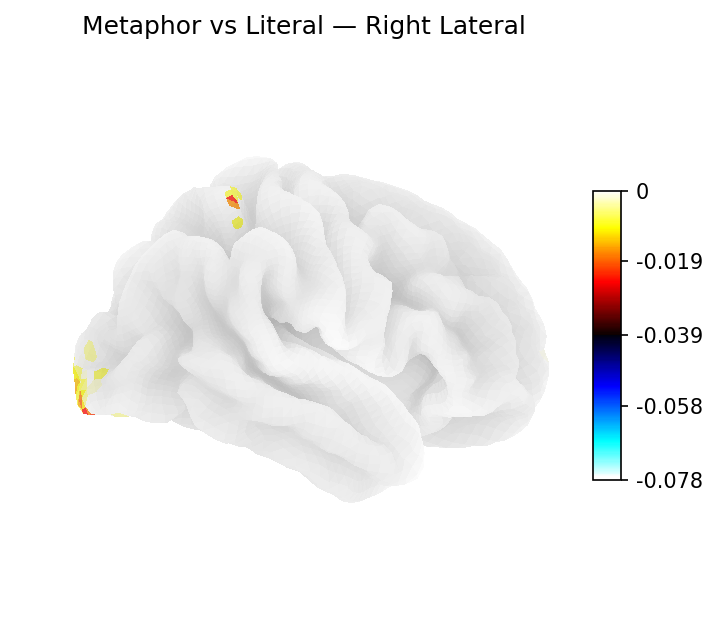
Classifier weights — Right lateral
Logistic regression weights on the right lateral surface.
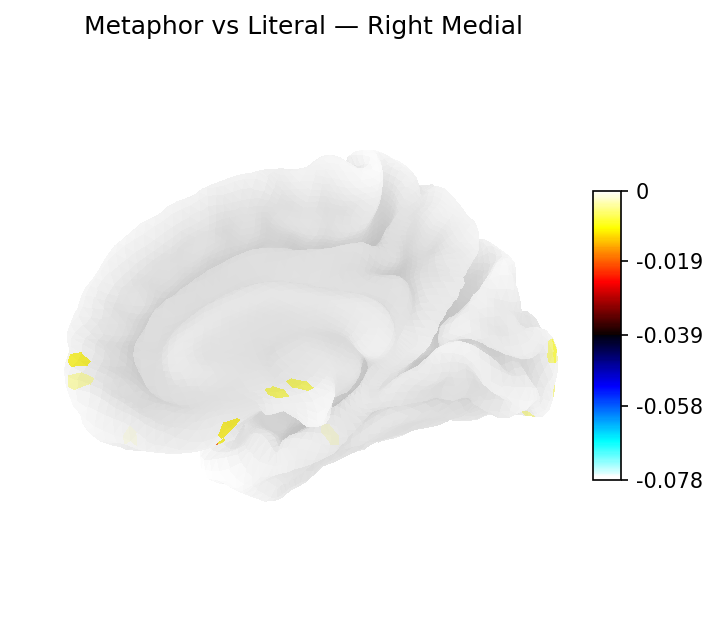
Classifier weights — Right medial
Logistic regression weights on the right medial surface.
Experiment data excludes raw stimuli and large prediction arrays.
Back to experiments